Scraping TripAdvisor reviews using Python
We’re going to use scrape review data from Tripadvisor, which would be helpful if you wanted to do a NLP analysis of reviews as a way to keep your finger on the pulse of customer satisfaction.
Selenium is a tool that lets you control your desktop browser programmatically. Tripadvisor requires a "read more" button to be clicked to reveal the entire review, and Selenium is a good tool to easily get this done.
Install Selenium
We’ll assume you’re using Anaconda for environment management. First, activate an environment with
conda activate [environment]
Install Selenium with:
conda install -c conda-forge selenium
Import packages
The first thing we’ll do is import the required packages. There aren’t many:
import csv #This package lets us save data to a csv file
from selenium import webdriver #The Selenium package we'll need
import time #This package lets us pause execution for a bit
Define variables
We'll need to set up some variables.
First, define a path and file to store data. Here I'm just putting it on my Mac's desktop
path_to_file = "/Users/chris/Desktop/HotelReviews.csv"
Next, define the number of review pages to scrape. There might be hundreds of pages of reviews, depending on the property. For this demonstration we'll keep it easy and just grab three pages.
pages_to_scrape = 3
Next, define the Tripadvisor URL. We'll use the Hilton Waikiki resort page, because it's a super nice hotel!
url = "https://www.tripadvisor.com/Hotel_Review-g60982-d209422-Reviews-Hilton_Waikiki_Beach-Honolulu_Oahu_Hawaii.html"
Get Selenium on the right page and set up the CSV
Let's launch Selenium and have it point the browser to the URL we're using. This example uses the Safari browser, but you can remote control Chrome (or any other browser) if you prefer.
# import the webdriver
driver = webdriver.Safari()
driver.get(url)
We'll also get a CSV set up to contain the data we retrieve
# open the file to save the review
csvFile = open(path_to_file, 'a', encoding="utf-8")
csvWriter = csv.writer(csvFile)
Programmatically grab the reviews, one after the other
Now it's time to tell Selenium to grab the reviews. Because Tripadvisor reviews are truncated, we'll be sure and click the "read more" button for all reviews first.
# change the value inside the range to save the number of reviews we're going to grab
for i in range(0, pages_to_scrape):
# give the DOM time to load
time.sleep(2)
# Click the "expand review" link to reveal the entire review.
driver.find_element_by_xpath(".//div[contains(@data-test-target, 'expand-review')]").click()
# Now we'll ask Selenium to look for elements in the page and save them to a variable. First lets define a container that will hold all the reviews on the page. In a moment we'll parse these and save them:
container = driver.find_elements_by_xpath("//div[@data-reviewid]")
# Next we'll grab the date of the review:
dates = driver.find_elements_by_xpath(".//div[@class='_2fxQ4TOx']")
# Now we'll look at the reviews in the container and parse them out
for j in range(len(container)): # A loop defined by the number of reviews
# Grab the rating
rating = container[j].find_element_by_xpath(".//span[contains(@class, 'ui_bubble_rating bubble_')]").get_attribute("class").split("_")[3]
# Grab the title
title = container[j].find_element_by_xpath(".//div[contains(@data-test-target, 'review-title')]").text
#Grab the review
review = container[j].find_element_by_xpath(".//q[@class='IRsGHoPm']").text.replace("\n", " ")
#Grab the data
date = " ".join(dates[j].text.split(" ")[-2:])
#Save that data in the csv and then continue to process the next review
csvWriter.writerow([date, rating, title, review])
# When all the reviews in the container have been processed, change the page and repeat
driver.find_element_by_xpath('.//a[@class="ui_button nav next primary "]').click()
# When all pages have been processed, quit the driver
driver.quit()
Conclusion
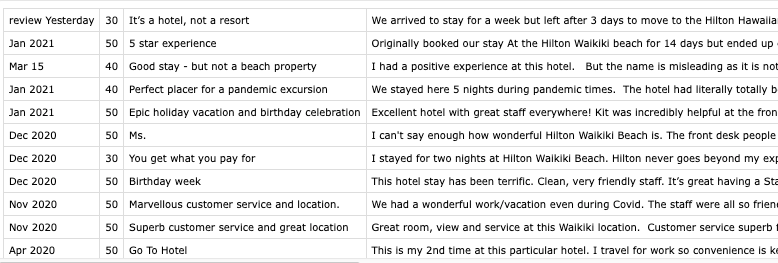
That's it! A very simple program. You'll now have a csv that contains all the reviews you retrieved, looking something like this: